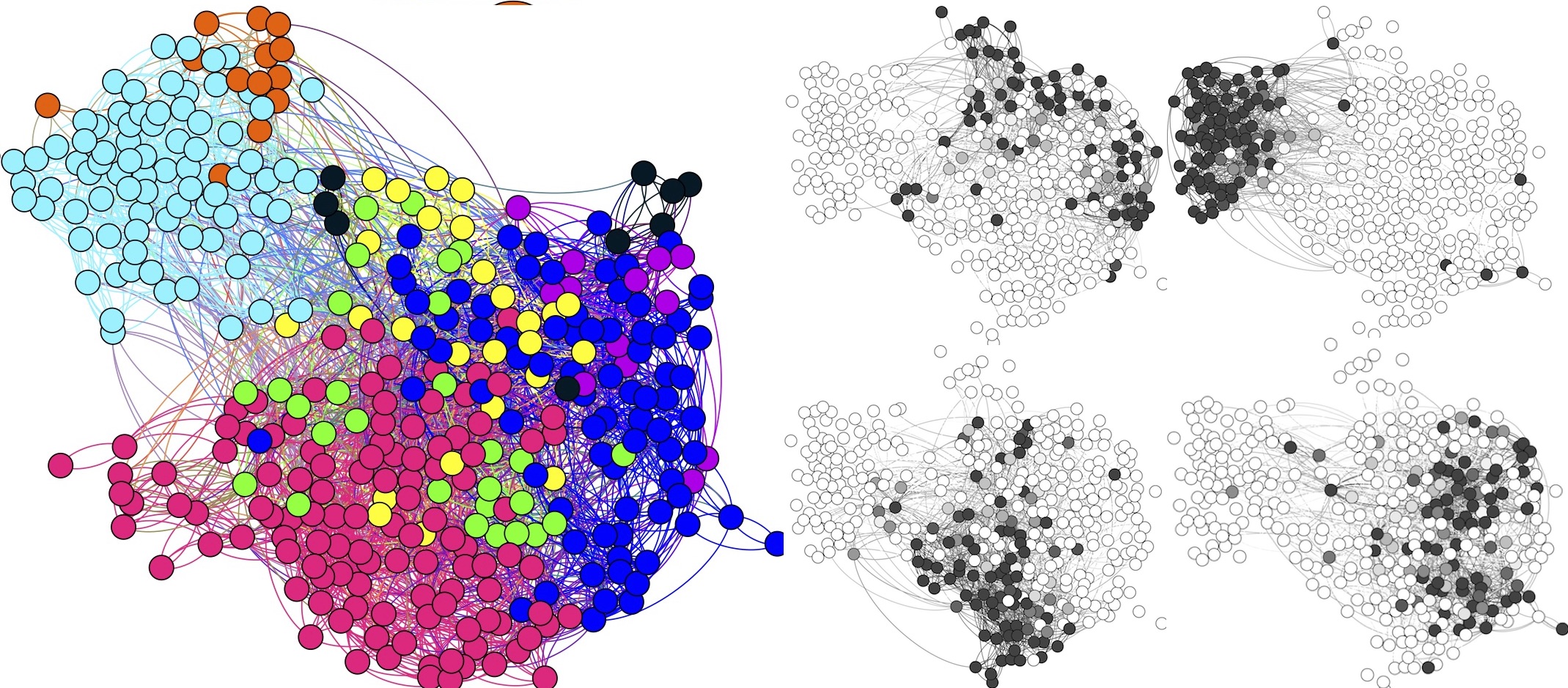
Division by caste membership for an Indian village (left). To the right we see the membership inferred in each of the four community, with color ranging from white for nodes not belonging to that group, to black, for highest membership in that group.
One of the main problems when working with real-world data is the absence of ground truth. The structure predicted by a model might not, in general, correspond to the structure suggested by additional information, such as metadata or covariates associated to nodes or edges of the network. Nevertheless, this additional information might bring in new insights to the problem, therefore it is very important to understand how to use this information, either to guide pattern prediction or to asses a posteriori how the results correlate with the metadata. We investigate modeling approaches capable of incorporating metadata for detecting communities on multilayer networks. In particular, we are interested to analyze how this additional information influences the resulting node partitions in real datasets. Knowing how the metadata contributes to clustering nodes can provide useful insights to understand the mechanism driving the observed topology. This can, for instance, be used to predict the connection of nodes for which we only know metadata but not their patterns of interactions. In addition, one can use the metadata to steer the detected partition towards a given type of division, by selecting which metadata to be incorporated based on the details of the problem considered.